AI 十讲(二)- 运动计划垂直模型实录
1. 引言
为什么要构建运动计划的垂直模型?在当时,我们主要基于四个维度的考量:
- 满足用户个性化需求:长期以来,有不少用户负反馈,比如未满足复杂的伤病问题(膝盖和腰都疼),未满足个人运动偏好(不喜欢波比跳),未满足特定目标(只想练胸)。
- 突破商业模式:在线运动计划往往被视作一种转化工具,类似于健身房的年卡。用户为了解决焦虑而付费,但这导致了极低的使用率和续费率,无法形成长期有效的商业价值。
- 追求真正好用的健身计划:我们希望设计出一套不仅仅针对减脂的运动计划。减脂用户往往只关心热量差,运动计划的设计对用户来说根本不重要,他们也不关注运动科学。然而,健身计划涉及到的结构平衡、分化训练、周期化训练以及伤病预防等问题,是需要以运动科学为基底的。
- PR 需求与技术壁垒构建
2. 构建评估体系
在开始训练模型之前,最重要的一步是定义什么是好的运动计划。我们构建了一套包含离线与在线的双重评估标准。
离线指标主要分为 3 个大方向,个性化、科学性和安全性。
- 个性化维度又细分为用户需求的满足度,用户目标的满足度,能力经验的匹配度等
- 科学性包含了运动科学的满足度,分化渐进的满足度等
- 安全性包含了伤病的满足度,结构平衡的满足度,疲劳恢复等。
通过 10+ 轮的迭代,我们构建了一套以 LLM-as-a-Judge 的自动化评估为主 + 人工抽查 Review 为辅的评估体系。
在线指标主要从用户侧和商业化的角度看,像应用率和复购率,这部分主要通过 AB 实验来评估。
2.1 LLM-as-a-Judge
我们并没有简单地扔给大模型一个 Prompt 让它打分,而是经历了 10+ 轮迭代。
每次抽取 300 个 Case 左右,通过 Review 分数比较高的和分数比较低的 Case,通过提示词优化,数据分布调整等,让 LLM-as-a-Judge 能自动跑起来。
评估模型要优先选择细分场景里最强的模型。
2.2 混合专家投票
单一大模型的评估存在随机性,为了提升评估的可信度,我们设计了两种投票机制:
单模型多次采样:对同一个计划,让评估模型在不同 Temperature 下评估多次。Temperature 为 0.05 时,评估结果比较稳定。
多模型加权投票:同时引入 GPT-4o、Claude 3.5 Sonnet 以及 Gemini 2.5 Pro 进行打分。
2.3 与人类专家的对齐
我们每次迭代会抽取 300 样本,让人类运动科学专家和 LLM Judge 同时打分。通过不断调整 Prompt,最终将机器评分与专家评分的相关性提升到了 0.85 以上。这意味着,我们拥有了一把可以 24 小时工作的“专家团队”。
3. 数据构建
在大模型微调中,数据的质量和多样性远超数量。我们构建了 20,000+ 条高质量、多样化的数据集。
3.1 数据的多样性构建
为了防止模型过拟合到某一类用户,我们设计了一个用户画像生成器,覆盖了 40+ 个维度:
生理特征:BMI、体脂率、伤病史(膝盖、腰椎、手腕)。
环境约束:居家/健身房、器械、时长。
运动偏好:喜欢跑步、喜欢帕梅拉课程等。
3.2 数据的清洗与增强
- 基于规则的数据清洗和去重
- 基于模版的数据自动生成
- 复杂需求的数据构造
- 10000+ Reddit 数据补充
- 人工高质量数据的扩散
经过几轮迭代,我们合成了接近 2 万条数据,分布和线上用户基本一致。
3.3 推理数据生成
利用更强大的模型 Claude 3.5/Gemini 2.5 Pro 生成推理数据,Gemini 2.5 Pro 胜出。通过 Gemini 2.5 Pro 的 Prompt Engineering 强制模型在生成 JSON 之前,先输出一段
3.4 人工 Review 和用户反馈
建立每日人工 Review 和用户反馈 Case 的自动更新,重点关注表现好的数据和表现差的数据。
4. 模型训练
4.1 Base 模型选择
首先对当前 SOTA 模型进行了全方位的基准测试,评估对象:GPT-4o、Claude 3.5 Sonnet、Gemini 2.5 Flash、Gemini 2.5 Pro,DeepSeek-V3、Qwen2.5、Doubao-1.5-Pro 等主流模型。Gemini 2.5 Pro 也是全面领先,当时就跟小伙伴说可以买入 Google 的股票。(:2025 年 5 月时入手至今也有 100%+ 的收益了。
接下来选择了 Qwen2.5-32B 作为 Base 模型,后续也尝试过 Qwen3-8B、QwQ-32B、Qwen3-next-80b-a3b 以及 GPT-OSS-20B。
在垂直的场景里面,可以优先尝试 Dense 模型,大概率是比 MoE 模型的效果要好。
4.2 SFT
我们在 SFT 阶段采用了 LoRA (Low-Rank Adaptation) 技术,在保证效果的同时大幅降低了显存占用和训练时间。
微调的框架:LLaMA Factory 和 Unsloth。前期用 LLaMA Factory 比较多,后期用 Unsloth 更多,Unsloth 的性能更好。
炼丹:大概训练了 50 次左右,除了 Base Model 不同外,过程中最重要尝试是 LoRA Rank、Target Modules 和 Cutoff Length。
- LoRA Rank/LoRA Alpha,只要内存不爆,选大一点
- Target Modules,只要内存不爆,无脑选 All
- Cutoff Length,统计你的数据里面的长度,效果不好可能是 Cutoff Length 太小了
- LoRA Dropout
- Learning Rate/Epochs/Batch Size
4.3 GRPO/DAPO
数据构建:
- 用户聚类后的画像,从历史日志中捞取不同计划用户开练和用户没开练的数据
- 用户反馈的数据样本
混合奖励函数:
R_{total}=w_1*R_{online}+w_2*R_{offline}+w_3*R_{length_penalty}
框架:基于 veRL 的 DAPO ( Cipher-High 和动态裁剪)
4.4 工程优化
为了减少延迟和支撑线上的并发,我们在推理侧也做了优化,这里面不得不说 Doubao 的性能优化还是很牛逼的,在参数规模(8B vs 230B/23B)和输入输出 Token(~500 vs ~2000),居然推理时间只比 Doubao 少 50%。
- 量化: 将模型量化至 4-bit/8-bit。在精度几乎无损 < 2% 的情况下,显存占用减少 60%,推理速度提升 2 倍。
- PD 分离: 我们将 Prefill(预填充)和 Decode(解码)阶段分离到不同的计算节点,显著降低了首字延迟(TTFT)。
- 输出压缩: 训练模型输出简化的 Token 序列,再通过后处理减少了约 50% 的生成 Token 数。输出压缩的收益也大于输入压缩。
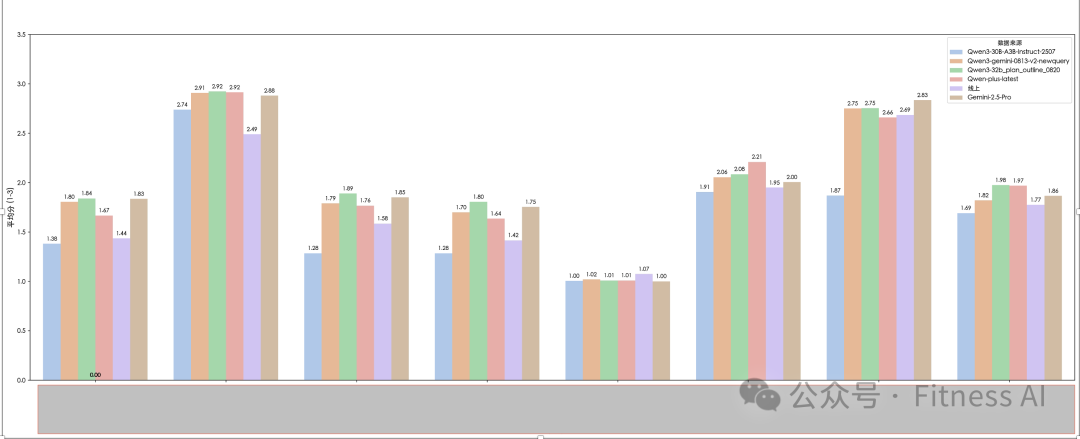
4.5 结果
微调版本的 8B 模型在各项指标上均追平了 Gemini Pro 2.5,大幅领先线上的模型,延迟也大幅减少,单词请求的 Token 量也少了 70%。但线上的用户数据和商业化数据几乎没有提升,主要收益来自于成本和 Token 的节省。
未来
回过头来审视这三个月的工程实践 - 我们需要诚实地回答一个问题:如果重新来过,还要做这件事吗?
SOTA 大模型在逻辑推理与领域知识上已形成碾压之势,即便是垂直场景的指令遵循,通用大模型和垂直模型也已不分伯仲。更重要的是迭代成本:SOTA 大模型只需修改 Prompt 或者改改工程代码,而微调模型却需要重新清洗数据和重跑训练。此外随着大模型厂商 Infra 能力持续提升,推理成本正以 5-10 倍的速度持续下降,微调模型仅存的成本优势也正在被时间抹平。
正如开篇所提,在线运动计划常被视作一种转化工具,用户通常是为了解决焦虑而付费。然而,缺乏训练过程数据的计划,其价值依然有限。随着健身意识的逐步提升以及多模态实时监测与反馈技术的不断发展,当 AI 能够像真人教练一样观察并纠正用户时,一份科学的个性化运动计划才真正具备了灵魂。