AI 十讲(一) - 打造属于你的数据中心
引言
我们每天都在产生海量的数据,但它们此刻正散落在微信的聊天记录、各类云相册、个人电脑、以及 NAS 的硬盘中,这是你未被开采的数字资产。
即使 ChatGPT 已经读遍了整个互联网的数据,它依然是一个熟悉的陌生人:它不知道你 2018 年秋天在东京拍过什么照片,也不记得你上周在微信里对孩子许下的承诺。
想要拥有一个真正懂你的个人智能体(Personal Agent),第一步不是打磨Prompt,更不是训练模型,而是先构建属于你的个人数据中心(Personal Data Center)。
文本数据
微信聊天记录
微信是所有个人数据里面最有价值的,但导出数据又是最麻烦的。以下内容仅探讨个人数字资产导出的技术实现路径,本人声明对于微信数据的导出仅供自己使用,且不对外提供任何技术服务。
1. 获取 wxid 和 key
这一步涉及到从内存中读取数据,不同的微信版本的方式会有差别,推荐使用 4.0.3.x 的版本。拿到当前进程的 pid、version、account_name、nickname、phone、wxid、wx_dir(微信文件的目录) 和 key(密钥)。
2. 解密 db_storage,用上面拿到的 Key 来解密 SQLite 格式的数据。
3. 导出聊天记录,可以导出不同的格式,TXT/HTML/Markdown,如果后续主要是给大模型来处理,那 Markdown 的格式就可以。92G 和 12G 的微信数据,大概处理时间在 35 分钟和 6 分钟。
注意:确认自己具备数据安全防护的能力后,可以把解密后的数据保存到私有存储,比如自建 NAS 中。一旦失去了微信的加密保护,这些包含你所有隐私的明文数据,是不建议上传至任何国内的云盘。
注意:如果提示微信版本太低的话,需要升级的话,可以使用 Cheat Engine。
4. 可以通过 API 将 Markdown 文件给 Gemini 3 Pro,让它基于聊天记录分析和给建议,看看下面几个例子,我觉得是有一定的参考价值。
个人笔记(Notion)
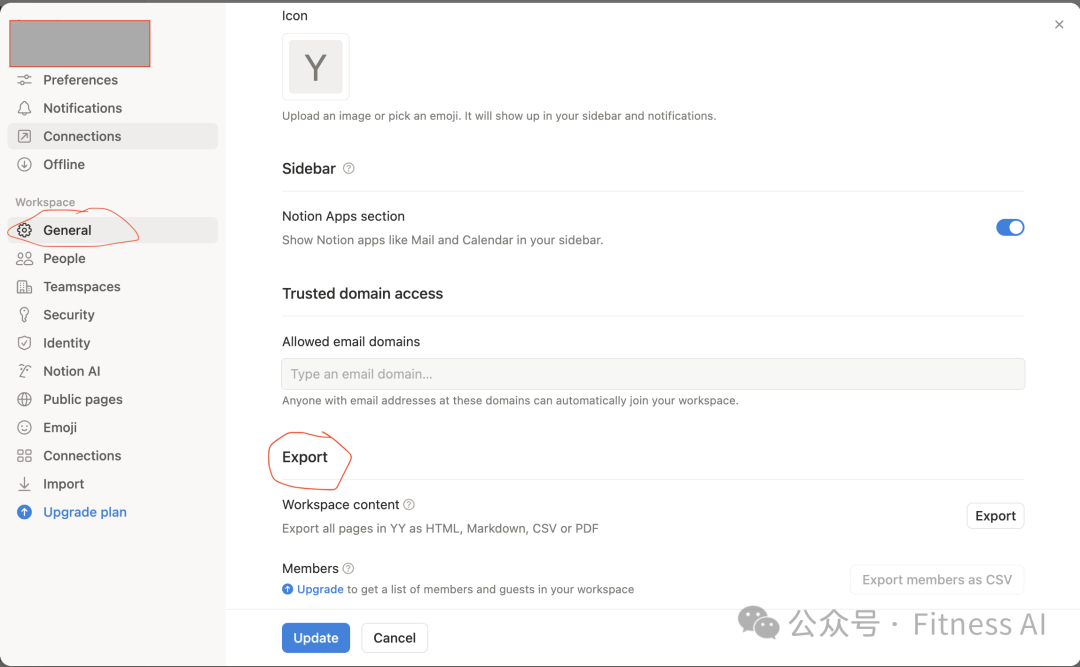
1. 点击 “Workspace” (工作区) 下方的 “Settings” (设置) 标签。
2. 找到 "General" (通用) 的 Export 选项,Export All Content。
个人文档
在使用飞书等企业协同软件时,请务必清楚工作期间产生的数据所有权归属于公司。管理员不仅可以通过审计模块调取你的聊天、邮件和文档,还能设置敏感行为报警。因此,离职时的资产交割会非常受限,可以提前做好核心文档的本地备份。
还有一个公私数据隔离的原则:非工作数据请保留在个人微信中。虽然微信的数据导出门槛极高,但它能确保你的隐私不被公司的审计系统穿透。
我最近将解密后的数千本 Kindle 电子书和 NAS 文档备份到了 NotebookLM(请认准官方域名 https://notebooklm.google.com/ )。作为下一代知识管理工具的雏形,NotebookLM 展现出的语义理解与跨模态整合能力,代表了从存储文件到理解内容的范式转移,这值得所有传统网盘产品学习。
音频数据
通话记录
iPhone 的通话自动录音一直没有开放,可能是因为苹果坚持录音必须要手动触发且要通知对方。
而 Android 手机大部分是可以开启通话自动录音的。
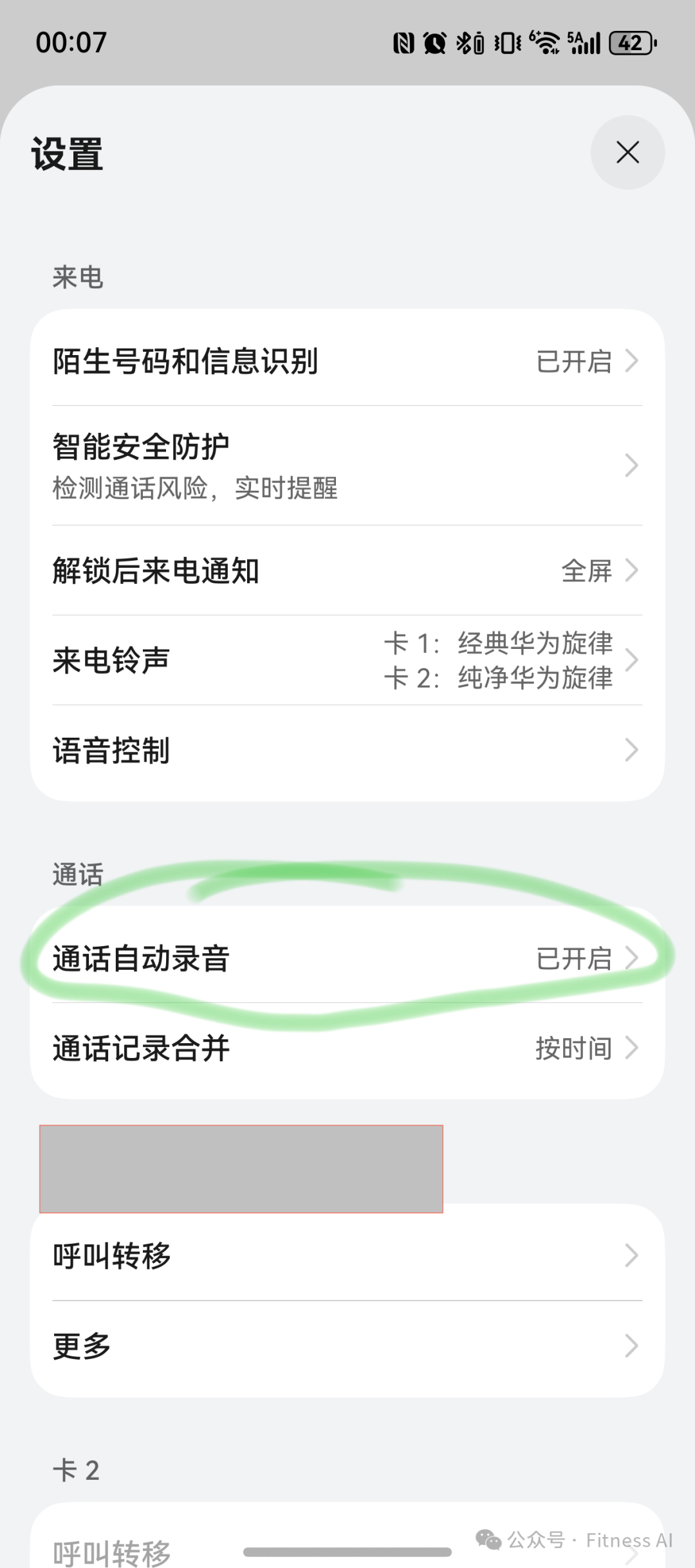
24 小时录音
最近给小孩佩戴了一个 24 小时录音的小硬件 Omi Dev2,跟飞书和安克合作的那个AI 录音豆有点像。但它的硬件的质量确实不太好,短短十多天已经玩坏一个设备了(幸好有先见之明,当时买了一对)。

在软件端,我参考了下面的项目定义一个自己的 App,把采集过来的音频数据做一些后处理,再转存到自己的 NAS 中。
https://github.com/BasedHardware/omi/
相比闭源产品,如果要把 24 小时的数据存储到他们的服务器,也不知道你的数据会被哪些人分析和处理。开源方案带来的数据主权与可控力就很重要了。目前,语音识别与语义分析技术已趋于成熟,如果硬件端能进一步提升续航与稳定性,这套 24 小时的音频采集系统将爆发更大的潜力。
在分析这些音频数据后,我发现三岁孩子的世界远比我们的想象丰富。她经常会自言自语,大部分是她对刚刚过去的事情的感受表达。另外三岁的小孩睡觉也是会打鼾的。
图片/视频数据
Google Photos
1. 去 https://takeout.google.com 导出所有的照片视频,建议单个文件的大小选择为 4G/2G,单个文件太大的话,当你网络不太稳定时,容易下载失败。
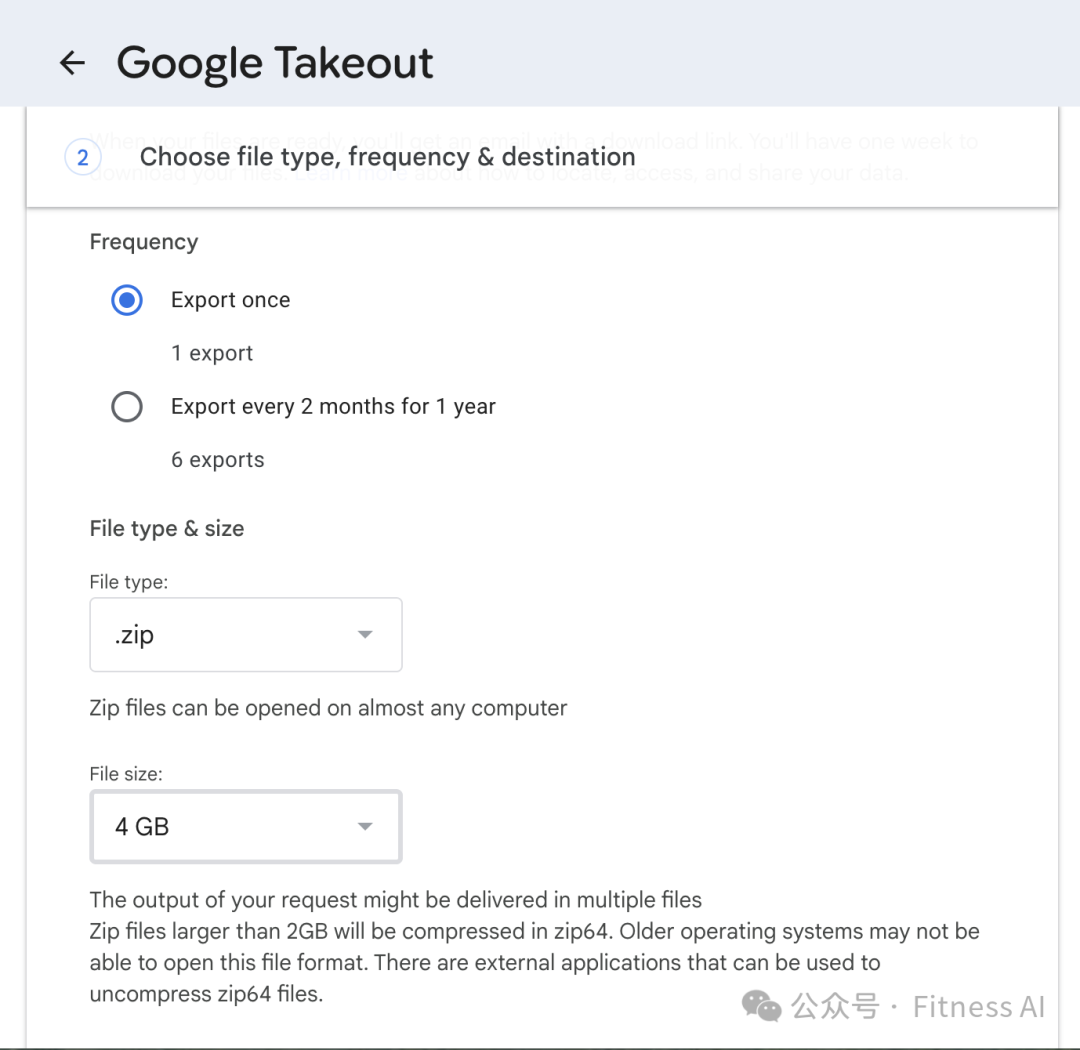
2. 将所有文件解压缩并合并到一个文件夹中,使所有 “Takeout” 文件夹合并为一个。
3. 利用 gpth 来把 Json 里面的数据回写到照片中,具体的可以参考这个项目:
https://github.com/TheLastGimbus/GooglePhotosTakeoutHelper
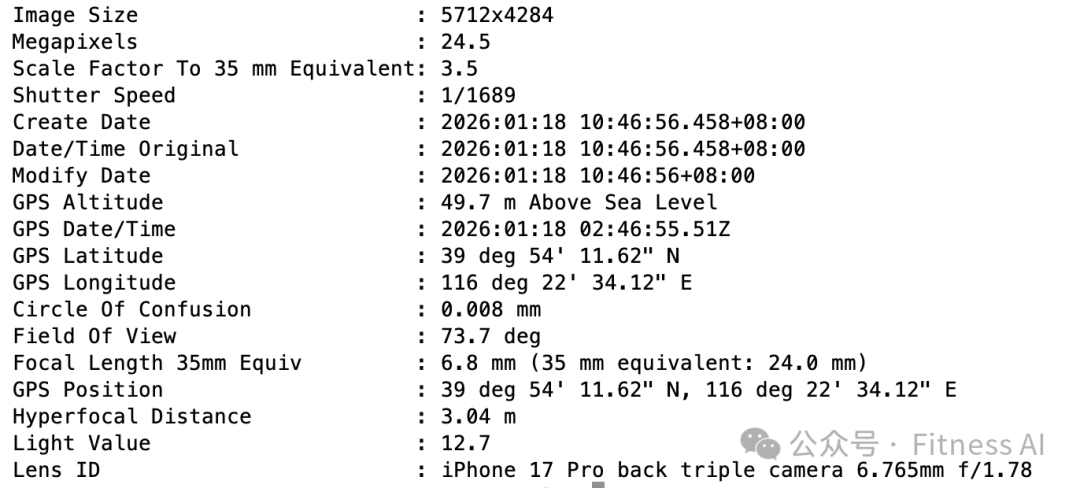
4. 用Exiftool 处理图片原始数据,重点处理是跟时间相关的(CreateDate、ModifyDate和DateTimeOriginal),以及跟地理位置相关的(GPSLatitude / GPSLongitude)。
5. 最近 Google Photos 也接入了 Gemini,在图片理解、人脸识别和语义搜索上比之前更强大了。可以在 Google Photos 直接 Ask:“2025 的精彩时刻,包含我的照片”,也可以直接 Ask 某段文字之类的。

iCloud Photos
方法一
1. 从 https://privacy.apple.com/ 获取你的数据副本
2. 下载后解压整理
方法二
如果照片数量不是太多,可以把照片同步到 Mac 的 Photos 上,然后从 Photos 里面导出。
注意:如果照片的数量比较多,我尝试的账号上有接近 30 万张,亲测即使在 M4 Pro 的顶配上,也卡到无法响应。
Synology Photos
1. 把来自于微信,Google Photo,iCloud,本地的照片,以及家人的照片(特别是有小朋友的,家人的图片重复的比例很高) 都导出来,备份到 NAS。
2. 修复元数据,如果有 Exif 信息,优先使用时间相关和空间相关的参数;如果没有,则通过文件名看看是否包含日期或者 Unix 时间戳;如果文件名也没有日期或者 Unix 时间戳之类的,则使用文件创建时间。
3. 去重,通过 Hash 和 Similar Image 去重,大幅减少图片的数量。保留的原则是:1️⃣ 保留原图,2️⃣ 保留时间最早的,3️⃣ 保留尺寸最大的。
4. 备份到 Synology Photos 作为一个原始数据的存储,推荐使用 Synology Photos(本地存储)+ Google Photos(云 + AI 能力) 的组合。
如何构建个人数据中心
通过前面的步骤,我们已经将微信聊天记录、个人笔记、文档电子书等文本流,通话录音、24小时全天候录音等音频流,以及 Google Photos、iCloud、Synology Photos 中的视觉流,全部清洗去重并整理到了 NAS 这一存储层。
同时,我们也有了 NotebookLM 和 Gemini 这样强大的应用来处理不同类型的数据。
然而,目前的链路是割裂的:图片视频归相册管,文档归笔记管,录音归播放器管。如果构建一个中间层,把不同模态的数据关联起来,比如把某次旅游/活动的录音,图片,聊天记录都能聚合起来,大家觉得这是个机会吗?
结语
欧盟(GDPR)第 20 条明确规定了数据可携带权 (Right to Data Portability),Google Photos 和 iCloud 的互通也证明了可行性,Notion/Apple Health 这些海外的应用也都提供了数据导出的功能。
而国内《个人信息保护法》第 45 条明确了个人有权查阅、复制其个人信息,且平台应当提供转移途径,但目前这仍停留在口号层面。大部分平台常以各种技术原因为由,仅提供极少量数据。当前的监管重心依然侧重于防泄露和防过度采集,对数据迁移和导出的执行力度远不及欧盟 GDPR。
在监管细则未落地之前,与其等待平台的施舍,不如主动出击。开始建立你的个人数据中心,将碎片化的信息转化为自主可控的数据,打造你在 AI 时代最核心的数字资产。